 prevalence
prevalenceHow it works
From a dataset too big to read to a number you can prove.
What you get is a measured estimate of how much of your data carries something you have to account for, with a margin of error and a written record of how it was produced. Not a scanner's raw count. A number your privacy or compliance lead can stand behind.
The flow
Four steps. Your reviewers, your computers, our math.
You never have to read the whole dataset, and you never have to take the detector's word for it. We sample it, your people label a small answer key, we correct for the detector's own error, and we report a rate with a margin of error.
We take a representative sample across the dataset, spread over your sources, so a small read stands in for the whole.
Your reviewers label a small answer key on your own computers. No documents leave your building.
We measure how often the detector is wrong, checking it against the answer key, and correct for that, source by source.
We report a rate for the whole dataset with a 95% margin of error, weighted back across your sources.
What you get
A real evidence pack, produced by the tool on made-up data.
This is the actual file the tool produces, run start to finish on made-up data with no real personal information. On the left, a handful of the input documents. On the right, the evidence pack the tool produced from them.
Sample input documents
Support volume dipped over the holiday and recovered by the second week. The vendor contract renews annually unless cancelled thirty days prior.
Documentation for the legacy endpoint was migrated to the new wiki space. The vendor contract renews annually unless cancelled thirty days prior.
The vendor contract renews annually unless cancelled thirty days prior. The intake form recorded SSN 074-81-6595. Replies were routed to arieltrujillo@maldonado.org.
Three of the corpus inputs, verbatim from sample_inputs.jsonl. The synthetic SSN and email are highlighted; these are fabricated, not real.
The evidence pack
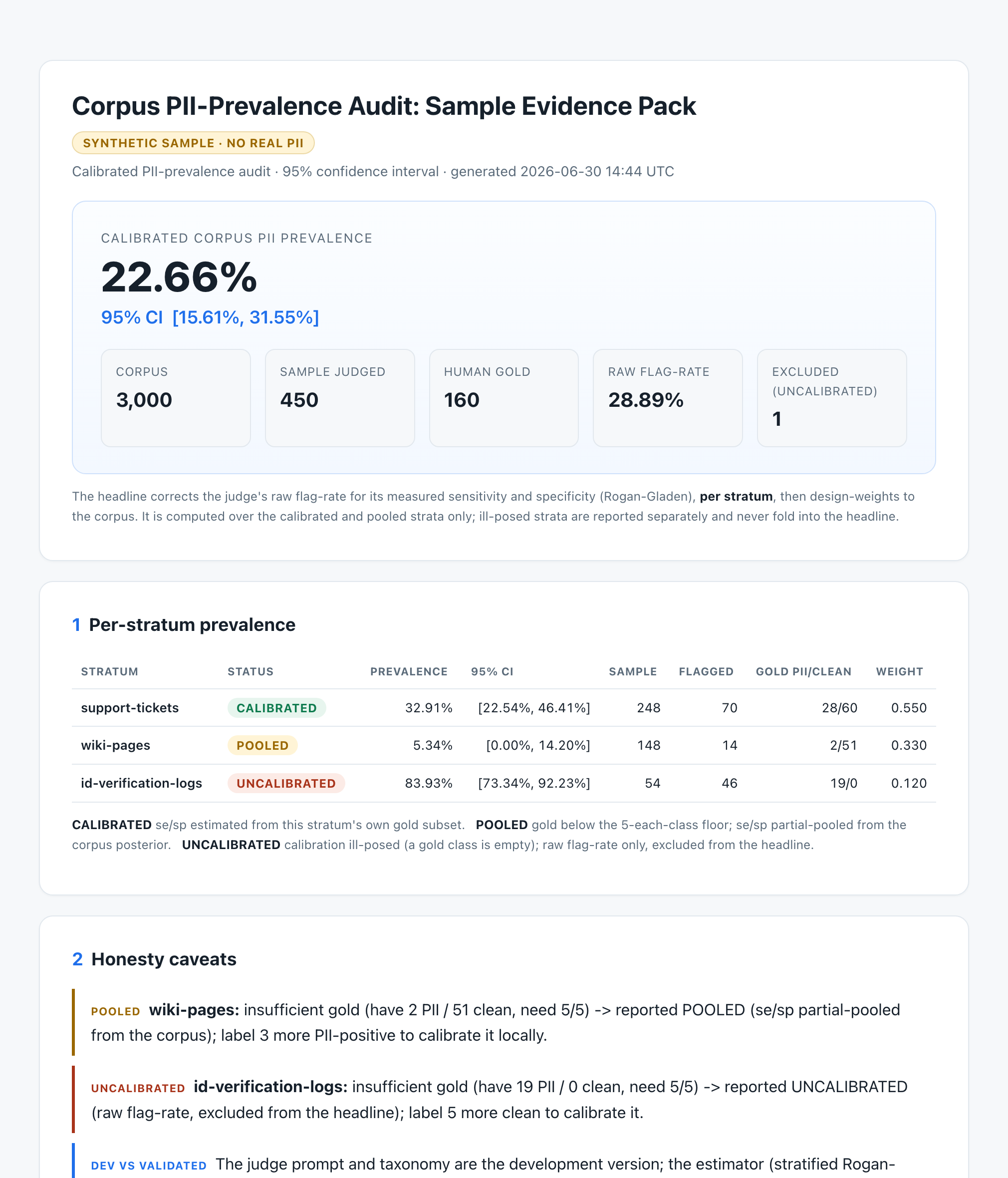
Headline: a calibrated 22.66% corpus prevalence, 95% CI [15.61%, 31.55%], over a 3,000-document synthetic corpus, 450 judged, 160 human-gold. The pack also carries the per-stratum breakdown, the honesty caveats, the method, and a reproducibility block.
The raw scan flagged 28.89%. Corrected for its over-flagging, the honest number is 22.66%. On most datasets the corrected number is the lower one, and the difference is redaction and review you can skip.
We tell you what we cannot calibrate
A slice with too little gold is flagged and excluded, never fudged.
An uncalibrated raw rate is untrustworthy: it still carries the judge's own error, so it says nothing defensible about the real prevalence. When a slice does not have enough human gold to calibrate, we do not quietly average it into the headline. We flag it and leave it out, and we tell you exactly how many more labels would fix it.
In this sample pack the id-verification-logs slice came back at a raw flag-rate of
83.93%
but its gold had zero clean documents, so calibration is ill-posed. The tool marks it UNCALIBRATED and excludes it from the headline rather than letting an uncorrected 83.93% inflate the number. That refusal is the point: it is what makes the 22.66% headline a figure you can defend, and it tells you to label five more clean documents to bring the slice in.
Same deliverable, three ways to get it
Run it yourself, certify one corpus, or have us run your estate.
You get the same calibrated evidence pack whether you license the tool and run it yourself (L), have us certify a single corpus as a Compliance Evidence Pack (C), or have us run and defend your whole estate as a Prevalence Diagnostic (D). The artifact above is what lands in every case. See the product and pricing page for the full ladder.
See it on your own terms
Walk a worked example with your numbers, or tell us the corpus and the exposure and we will come back with a sampling plan, a gold-label budget, and a fixed price.
All demo data is synthetic. We never ship real data out to audit your data.